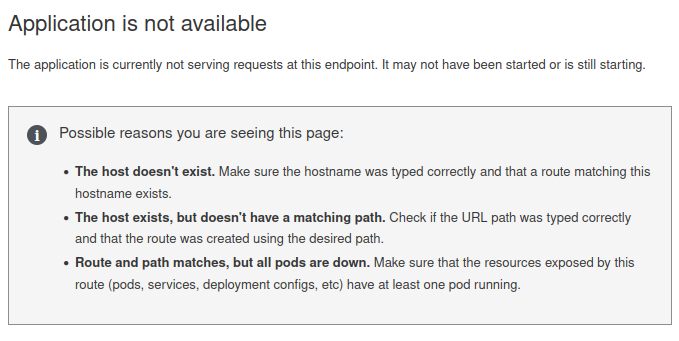
Ce serveur a fonctionné pendant 2 ans sans aucun soucis. Il y a 20 Go de Ram que se partage les pods.
Au niveau des logs, on trouve cela :
jetty@suite-starter-15-djrsx:/var/log/scenari$ cat scstatic_2023-12-11.log
1--- Info : Mon Dec 11 07:52:48 UTC 2023[746] (main) ---
================================================================================
Starting SCENARIsuite-starter 5.0 : SCENARIsuite-starter 5.0.101 202110061212 on OpenJDK 64-Bit Server VM 11.0.13+8-Ubuntu-0ubuntu1.20.04 / Linux amd64
1--- Info : Mon Dec 11 07:52:48 UTC 2023[760] (main) ---
OpenDocument editor found by env. var. 'PATH' in: /usr/lib/libreoffice/program
1--- Info : Mon Dec 11 08:07:47 UTC 2023[853] (main) ---
================================================================================
Starting SCENARIsuite-starter 5.0 : SCENARIsuite-starter 5.0.101 202110061212 on OpenJDK 64-Bit Server VM 11.0.13+8-Ubuntu-0ubuntu1.20.04 / Linux amd64
1--- Info : Mon Dec 11 08:07:47 UTC 2023[864] (main) ---
OpenDocument editor found by env. var. 'PATH' in: /usr/lib/libreoffice/program`
Dans le dossier jetty9, voici la fin de gc.log :
[2023-12-11T10:12:17.200+0000][34][safepoint ] Application time: 84.0106166 seconds
[2023-12-11T10:12:17.200+0000][34][safepoint ] Entering safepoint region: Cleanup
[2023-12-11T10:12:17.200+0000][34][safepoint ] Leaving safepoint region
[2023-12-11T10:12:17.200+0000][34][safepoint ] Total time for which application threads were stopped: 0.0000971 seconds, Stopping threads took: 0.0000216 seconds
[2023-12-11T10:16:19.231+0000][34][safepoint ] Application time: [242.0311083](tel:2420311083) seconds
[2023-12-11T10:16:19.231+0000][34][safepoint ] Entering safepoint region: Cleanup
[2023-12-11T10:16:19.231+0000][34][safepoint ] Leaving safepoint region
[2023-12-11T10:16:19.231+0000][34][safepoint ] Total time for which application threads were stopped: 0.0001582 seconds, Stopping threads took: 0.0000442 seconds
[2023-12-11T10:27:59.380+0000][34][safepoint ] Application time: [700.1488701](tel:7001488701) seconds`
La RAM alloué à Jetty à son démarrage est défini par JT_JAVA_OPTS, c.f. Docker
Vos instances Docker se partage peut-être 20Go mais le process Java de Jetty non, il utilise ce qu’on lui donne à son démarrage.
Par contre je ne vois rien dans les logs qui donnerait à croire que SCENARIsuite-starter soit en manque de RAM.
Vu de chez moi je trouve que vous avez en effet des problèmes, mais plus de réseau ?
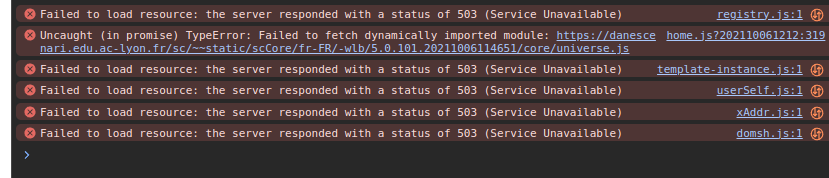
J’ai des latences au chargement des pages, et parfois des échecs du type :
Peut importe les différents messages JS côté client. De façon aléatoire on a des erreurs 503 sur tel ou tel ressource, dans votre exemple la requête https://danescenari.edu.ac-lyon.fr/sc/pub/ENT/Admin_ENT_web/lib-sc/scDynUiMgr.js était en 503, si vous faites F5 ce sera autre-chose, ou rien du tout, ou la page HTML elle-même ce qui donne le message que j’ai eu plus haut.
Il faut maintenant comprendre d’où viennent ces messages 503 il faut analyser les logs de Jetty et de scenarisuite-starter pour aller plus loin.
Les logs SCENARI sont dans le dossier /var/log/scenarisuite-starter5.0 ou on trouve un fichier par jour nommé comme suit : scstatic_2023-12-11.log
Il y a des chances que les logs Jetty sont dans le fichier /var/log/syslog, une commande comme grep jetty9 /var/log/syslog | less devrait montrer les logs Jetty mais cela dépends de comment Jetty a été configuré.
ensuite je ne sais pas comment vous avez paramétré l’accès HTTPS au serveur de servlet (Nginx ? Apache ?) il faudrait aussi voir ce qui ressors dans leurs logs et leurs accesslogs.
Il faut savoir que nous utilisons l’image Docker que @anp nous avait crée il y a déjà quelques années. Donc, nous n’avons pas tous les logs dans l’image.
J’ai mis les fichiers de log derrière ce lien. Je n’ai rien d’anormal hormis une erreur sur les gif anim mais c’était déjà existant.
En revanche, quand on a démarré le pod, on a eu cela :
Example reverse proxy: https://danescenari.edu.ac-lyon.fr/sc => http://CONTAINER_IP:PUBLISH_PORT/sc
2023-12-12 08:16:53.401:INFO::main: Logging initialized @824ms to org.eclipse.jetty.util.log.StdErrLog
2023-12-12 08:16:53.925:INFO:oejs.Server:main: jetty-9.4.26.v20200117; built: unknown; git: unknown; jvm 11.0.13+8-Ubuntu-0ubuntu1.20.04
2023-12-12 08:16:53.955:INFO:oejdp.ScanningAppProvider:main: Deployment monitor [file:///var/lib/jetty9/webapps/] at interval 1
2023-12-12 08:16:55.885:INFO:oeja.AnnotationConfiguration:main: Scanning elapsed time=0ms
2023-12-12 08:16:55.899:INFO:oejw.StandardDescriptorProcessor:main: NO JSP Support for /sc, did not find org.eclipse.jetty.jsp.JettyJspServlet
2023-12-12 08:16:56.071:INFO:oejs.session:main: DefaultSessionIdManager workerName=node0
2023-12-12 08:16:56.071:INFO:oejs.session:main: No SessionScavenger set, using defaults
2023-12-12 08:16:56.072:INFO:oejs.session:main: node0 Scavenging every 600000ms
2023-12-12 08:16:57.898:INFO:oejsh.ContextHandler:main: Started o.e.j.w.WebAppContext@707194ba{sc,/sc,file:///tmp/jetty-0_0_0_0-8080-sc_war-_sc-any-11219609305025747473.dir/webapp/,AVAILABLE}{/var/lib/jetty9/webapps/sc.war}
2023-12-12 08:16:57.907:INFO:oejs.RequestLogWriter:main: Opened /var/log/jetty9/2023_12_12.request.log
2023-12-12 08:16:57.937:INFO:oejs.AbstractConnector:main: Started ServerConnector@711d1a52{HTTP/1.1,[http/1.1]}{0.0.0.0:8080}
2023-12-12 08:16:57.938:INFO:oejs.Server:main: Started @5361ms`
Je pense que tout est normal car je viens de comparer avec une autre install Docker et j’ai exactement les mêmes messages.
Dernière précision, un collègue a réussi à extraire des .scar des cours en limitant, dans les options développeurs de Chromium, la bande passante à 50 Ko. Bref, tout est bizarre et on ne sait plus où chercher
J’imagine que le fichier « 2023_12_12.request » correspond aux accesslog de Jetty. Je n’y vois aucune requete en 503 là dedans.
Pouvez-vous joindre l’accesslog du reverseProxy (nginx ?) ?
Tu peux regarder dans les logs de jetty, pour le même horodatage « 14/Dec/2023:09:29:43.021 », ce que retourne la requête sur /sc/~~static/scCore/fr-FR/-wlb/5.0.101.20211006114651/core/user.js ?
Si c’est bien 200, cela confirmera un pb sur votre reverse proxy « HAProxy ». Retour du ticket à l’équipe réseau donc ! (je ne connais pas HAProxy, mais il y a très certainement un fichier de logs d’erreurs)
Bon… On a enfin trouvé la cause du soucis, je le mets ici car cela peut arriver à d’autres je pense.
C’était un problème de routage interne dans l’openshift, un node semble avoir eu un problème.
Bref, c’est réglé. Merci à @sam et @anp pour le soutien et les pistes… Je précise que le serveur avait parfaitement fonctionné durant plusieurs années sans aucun soucis
Super que le réseau ait pu identifier/corriger le pb !
Je me permets de vraiment insister : la vieille version 5.0 est maintenant en statut « fin de vie » (cf versions-scenari
Pour des environnements en production, qui veulent bénéficier des correctifs et des mises à jour de sécurité, il n’est donc plus possible de reculer le passage en 6.2 (ou 6.1).